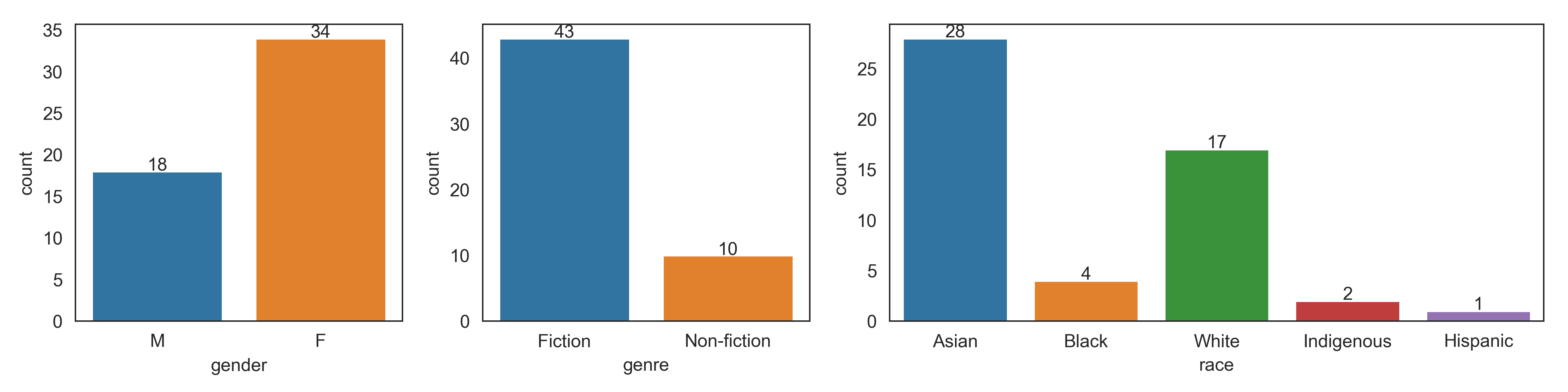
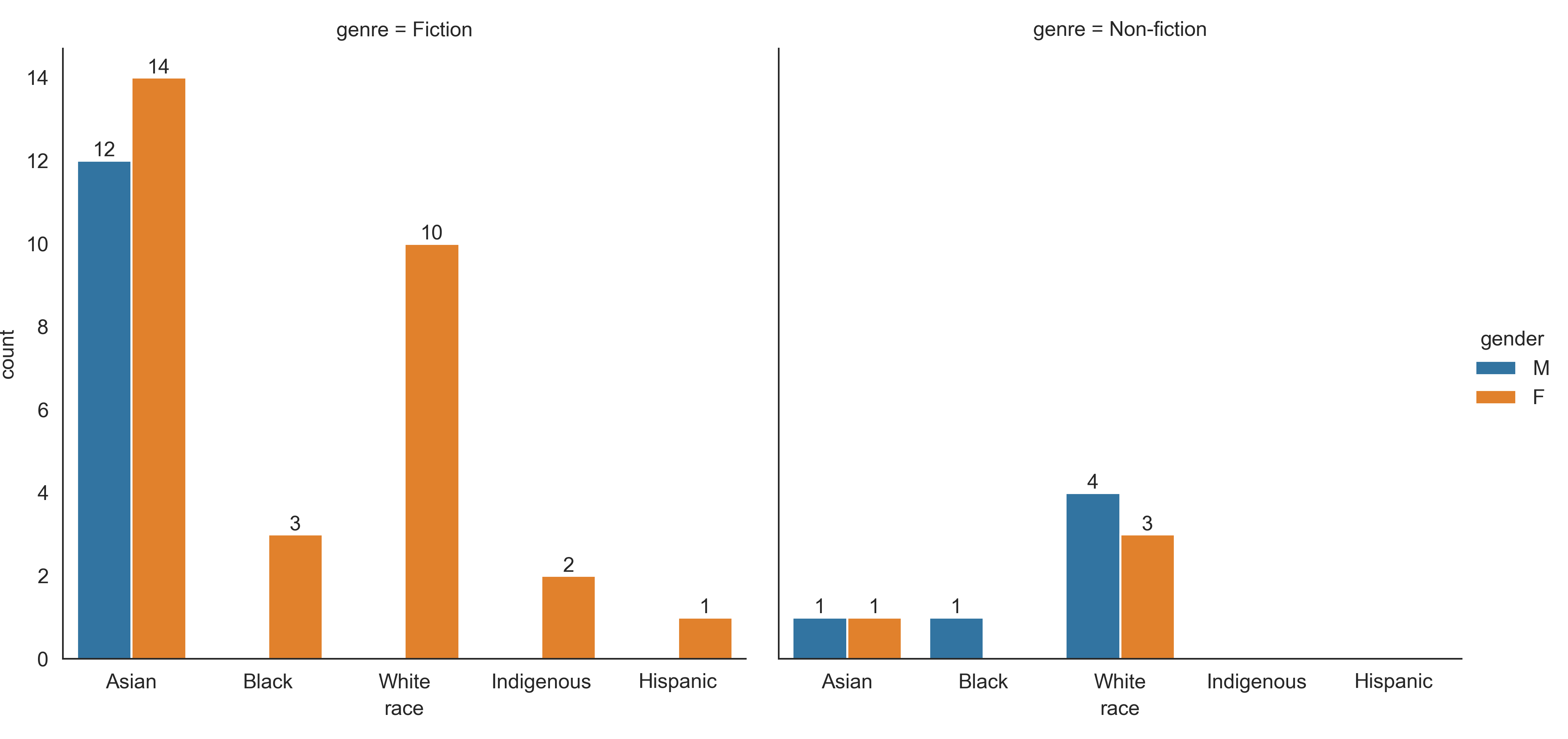
In 2020, my overall goal was still to read 50 books, and I met that goal by reading 65. Once again, although I don’t spend much time purposely diversifying my reading, most of what I met was fiction (51 / 65), by Asians (29 / 65), and by women (57 / 65).
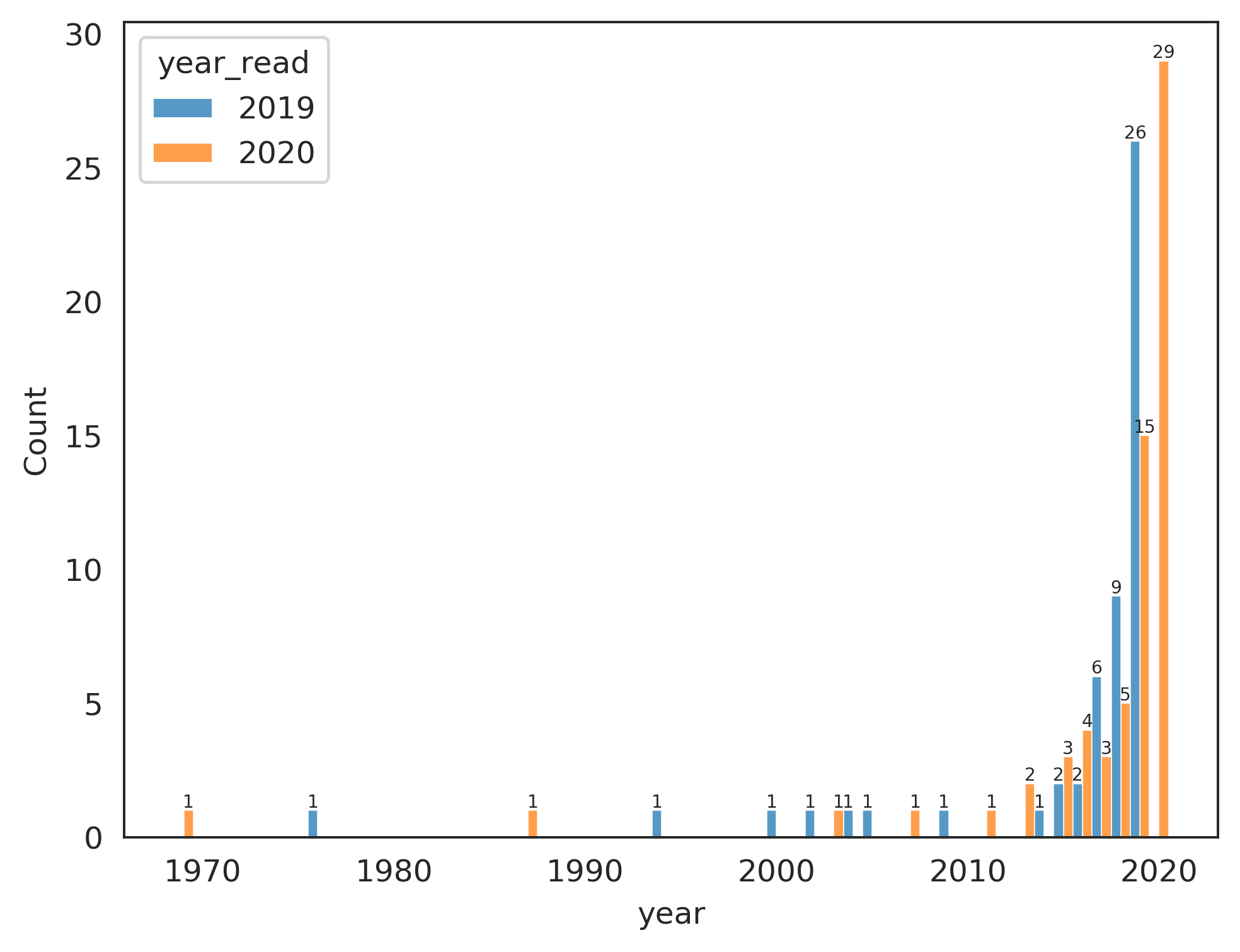
Here are the full comparisons between 2019 and 2020 overall:
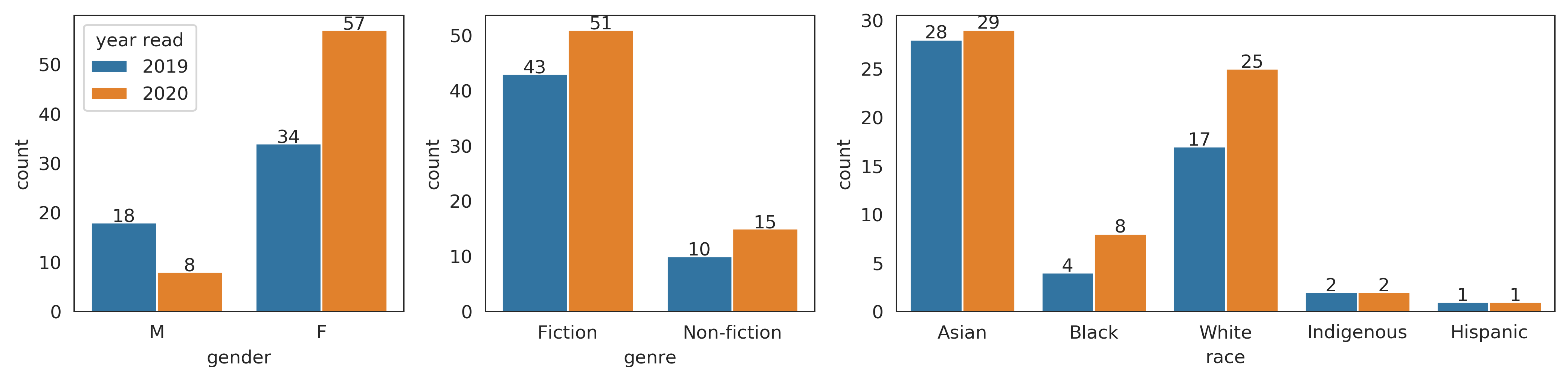
And broken down by fiction vs non-fiction:
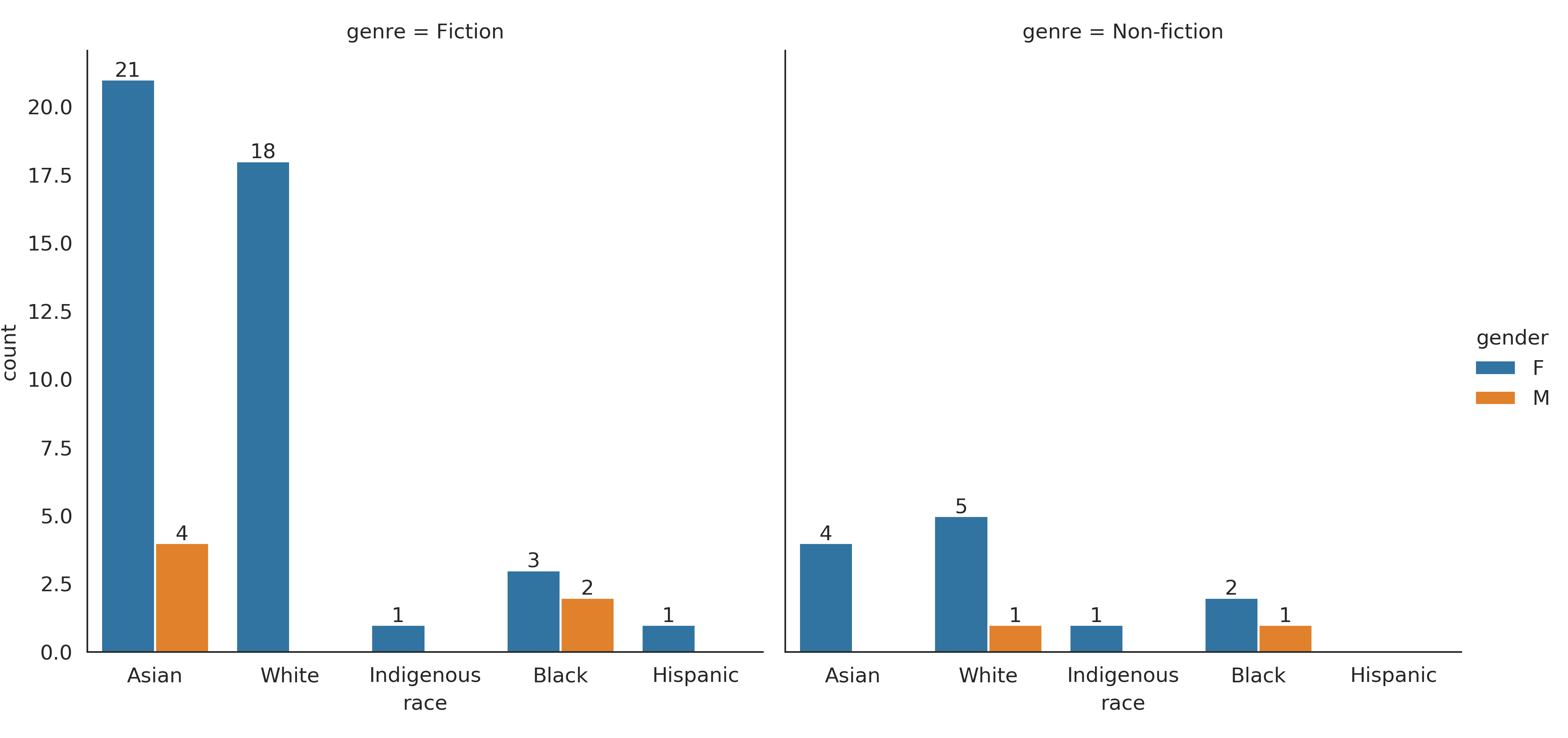
The 65 books were written by 54 unique authors. Of those authors, 41 were authors I had not read before.
2020 Resolutions
First, let’s review my 2020 reading resolutions and see how I did.
I should read a little bit more non-fiction.
Success! I increased my non-fiction reading in both absolute and relative terms.
I should read more books by Black, hispanic, and indigenous authors.
Mixed! I doubled the number of books I read by Black authors, but the number of books by hispanic and indigenous authors stayed the same. Most of the increase came from books by white authors.
I should read more older books.
Fail! 29 / 65 books were written in 2020, and another 15 were written in 2019. Like last year, I only read 2 books written before 2000. This one is pretty difficult for me because there’s so many good new books coming out.
Some Light 2021 resolutions
I should read more books by hispanic and indigenous authors.
I should read more older books.
Yes, I’m being lazy and just re-using the ones I didn’t do great on in 2020.
A Look Back at My Most-Anticipated Books for 2020
- The Burning God, by Rebecca F. Kuang: The highlight of my reading year.
- The Paper Menagerie, by Ken Liu: A masterful short-story collection, as anticipated.
- The City We Became, by N. K. Jemisin in March: sharp and hilarious. A very steep-departure from Jemisin’s earlier books in tone, but nevertheless very good.
- The Empire of Gold, by S. A. Chakraborty: A brilliant conclusion to the Daevabad triology.
- A Desolation Called Peace, by Arkady Martine: This one is now slated to come out in 2021.
- Big Sister, Little Sister, Red Sister, by Jung Chang: I managed to finish this crash-course in modern Chinese history, which helped a lot in understanding the historical background for the Poppy War series.
- Tears We Cannot Stop: A Sermon to White America, by Michael Eric Dyson: I don’t have much memory of this, but I did read it!
Highlights
The Burning God, by Rebecca F. Kuang
The searing conclusion to The Poppy War and The Dragon Republic was absolutely the highlight of my reading year. Nobody weaves brilliant story-telling, flawed yet compelling characters, and pain together as well as Kuang. I’ve written more about how much this series means to me here, and helped to write a post on the historical and cultural background behind the series.
Jesus and John Wayne, by Kristin Kobes Du Mez
Kobes Du Mez weaves many threads together to show modern white evangelicalism’s roots in preserving a certain vision of white manhood and patriarchy against 20th century gains by women and racial minorities. Along with Katherine Stewart’s The Power Worshippers, it clarified for me how white evangelicalism arose as reactions against the Civil Right Movement, Feminism, and continues now to react against the LBGTQ+ rights movement and Black Lives Matter as well as how evangelical social conservatives in the United States united with economic libertarians to create the American Right, the current iteration of the Republican Party, and Donald Trump. This one was also personal for me, as I grew up in enough of evangelicalism to recognize many of the figures in Jesus and John Wayne.
The Third Son, by Julie Wu
The Third Son tells the story of Saburo as he grows up in an abusive Taiwanese family underneath Japanese and then Nationalist rule and manages to break free by marrying his love, coming to the United States, and earning his PhD. The historical background is personal to me, as my parents also grew up in Taiwan and earned their PhDs in the United States (although they were firmly on the Nationalist side…).
The First Sister, by Linden A. Lewis
The blurb describes First Sister as space opera x Handmaid’s Tale, but that doesn’t really do justice to the book’s originality in conception and execution. I’ve read enough fiction now to often anticipate what’s coming in a novel, but every turn in this one surprised me.
The Mountains Sing, by Phan Qué̂ Mai Nguyẽ̂n
An epic account of a family’s experience in the Vietnamese War, as seen through the eyes of a girl and her grandmother. Nguyẽ̂n manages to capture the sweep of history along with intimate familial relationships.
An Ember in the Ashes, by Sabaa Tahir
I read all four of the books in this series this year. Tahir weaves a dark yet hopeful adventure in a dystopia that loosely resembles the Roman Empire. Like The Poppy War, this is another series where not many good things happen to the characters, but it never felt quite as dark and real to me as Kuang’s series.
Minor Feelings by Cathy Park Hong
Hong perfectly encapsulates the experience of being a “model minority” in the United States in a series of honest, emotional, and raw essays about shame and depression, the English language, and poetry. The titular “minor feelings” are “the racialized range of emotions that are negative, dysphoric,” yet not so spectacularly horrible as to be telegenic.
Books I’m looking forward to in 2021
A Desolation Called Peace should finally come out in March. Ken Liu’s Dandelion Dynasty trilogy has been expanded to a Quartet, and I believe both books are releasing in 2021. I’ve been seeing a lot of hype in Asian book circles for She Who Became the Sun, by Shelley Parker-Chan, and we can always use more modern, fantasy, queer, re-imaginings of ancient Chinese history. Jade Legacy, the conclusion to Fonda Lee’s Jade City series, is due out in September. The Second Rebel, which follows The First Sister, comes out in November.
The Complete List and Source Code
The full list is available here. The code to generate the plots is here
]]>