NeurIPS Day 1
I got to Logan at 4am yesterday and got to Vancouver 4 flights and 20 hours later. No, that was not the itinerary I’d originally planned. The first thing I did in Vancouver was get Taiwanese food in Richmond. The second thing was to go to the hotel and sleep. So I was pleasantly surprised to not feel too bad for the first day!
Some random thoughts
- NeurIPS is humongous. It’s spread over two multiple rooms in two buildings, and the whole place is crawling with people desperately trying to charge their phones and laptops. At one point, the evening poster session was full and they were turning people away.

- With that said, this is the first conference I’ve been to where I know people. Between people from my company, people I met at AIStats, and people who have reached out to me asking to meet, I really feel much more comfortable here than I have at any other conference.
- I wish the oral and spotlight titles were in the printed program. The conference app is ok, but it’s a fair number of clicks to find the talk titles.
- The sponsor booths here are much more impressive than they were at ISMB.
- Novartis and Benevolent AI are the only Biotech companines in the sponsor area. The rest of them really need to step it up and stop letting the financial companies have such an outsize presence.
- Sometimes it’s fun to go to a session about things I don’t really study (reinforcement learning, in this case)
- The dynamic range of talk quality is huge. I’ve started to just tune out talks after the second slide if I can’t follow.
Some papers I think are interesting
Combinatorial Bayesian Optimization using the Graph Cartesian Product
Changyong Oh, Jakub M. Tomczak, Efstratios Gavves, Max Welling
If you want to optimize over combinatorial input spaces, then it makes a lot of sense to encode them as graphs and use graph kernels.
Learning to Perform Local Rewriting for Combinatorial Optimization
Xinyun Chen, Yuandong Tian

More combinatorial optimization, this time by learning one policy that chooses what to change, and another policy that chooses how to change it. The policies are rewarded based on the final result, so this should do better than greedy.
A Simple Baseline for Bayesian Uncertainty in Deep Learning
Wesley Maddox, Timur Garipov, Pavel Izmailov, Dmitry Vetrov, Andrew Gordon Wilson.
A simple method for approximating the true posterior over neural network weights. Somebody needs to see how this does on the Deep Bayesian Bandits Showdown.
Scalable Global Optimization via Local Bayesian Optimization
David Eriksson, Michael Pearce, Jacob R Gardner, Ryan Turner, Matthias Poloczek
Bayesian optimization often breaks down in high-dimensional spaces because samples are too sparse or the uncertainty is too large near the edges of the search space, leading to over-exploration. Trust-region algorithms overcome this by limiting the search to an area around the current best solution and then fitting very simple models (linear, quadratic) in that region. The region grows or expands based on whether evaluations improve the optimum. Logically, fitting a GP and doing BO within the trust region performs much better.
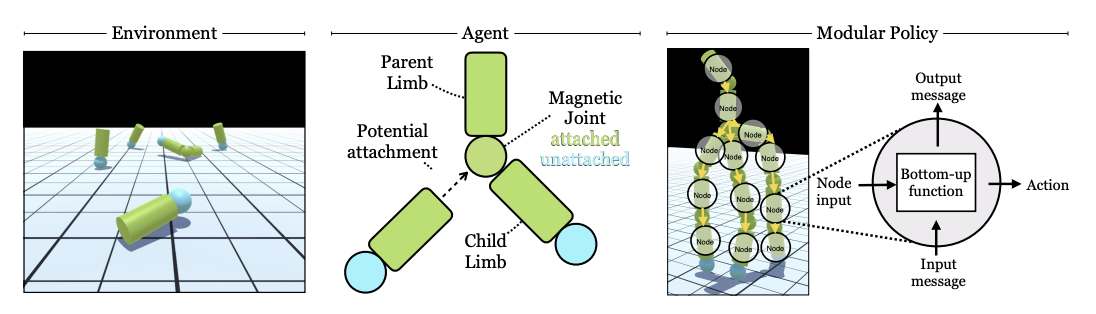
Learning to control self-assembling morphologies via modular co-evolution of control and morphology
Deepak Pathak, Chris Lu, Trevor Darrell, Phillip Isola, Alexei A. Efros
Just as biology began with simple structures (cells) and gained physical complexity in parallel with behavioral complexity, it can be easier to evolve a control policy in parallel with the thing being controlled. For example, we can learn a behavioral policy for simple magnetic arms that allows them to assemble in order to perform complex tasks.
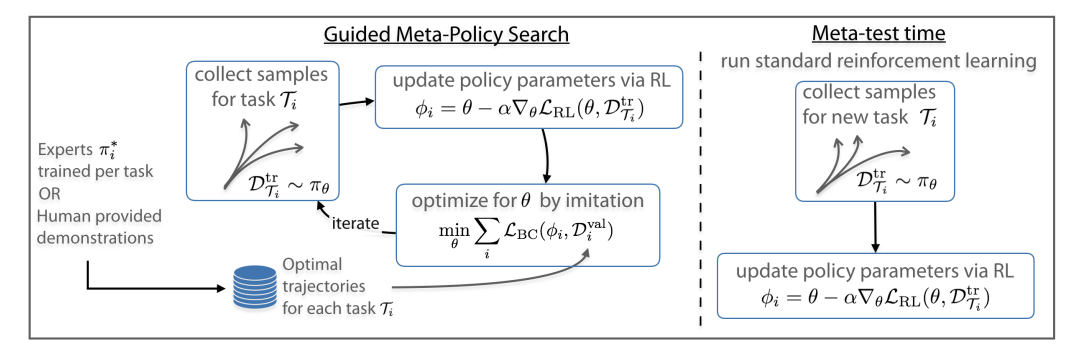
Guided meta-policy search
Russell Mendonca, Abhishek Gupta, Rosen Kralev, Pieter Abbeel, Sergey Levine, Chelsea Finn
Naively training a meta reinforcement learning policy that does well with few examples on new tasks requires an intractable number of samples. Instead, we can train on each of the training tasks individually, and then train the meta-policy using the individual policies as supervision signals.
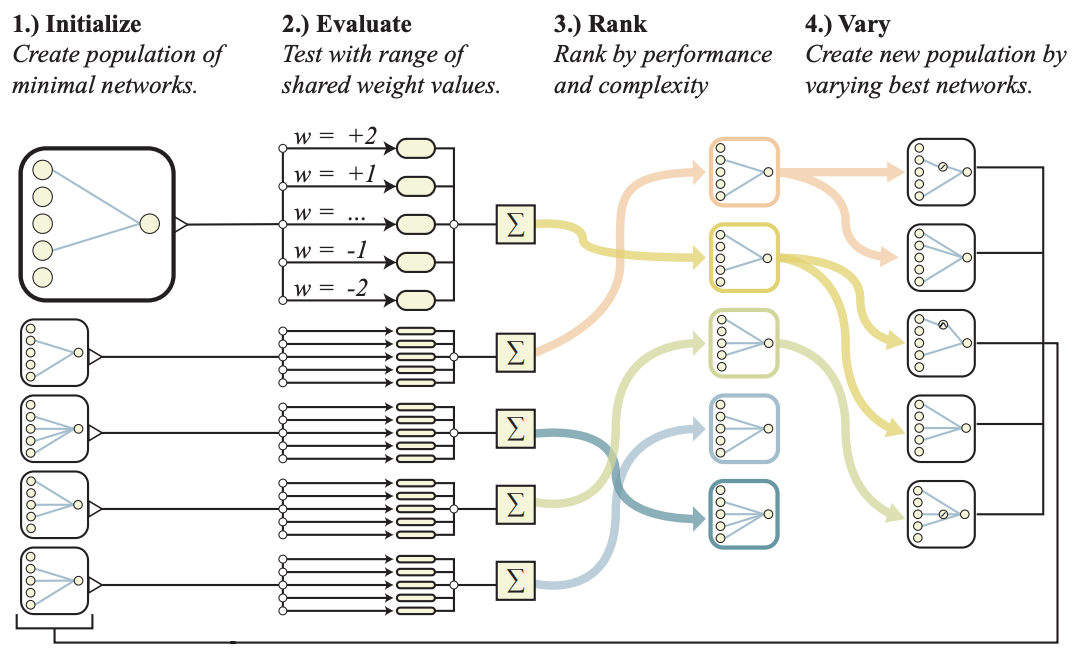
Weight agnostic neural networks
Adam Gaier, David Ha
Optimize over architectures instead over weights finds networks that are surprisingly good at RL and image classification even when all their weights are the same.