NeurIPS Day 2
Today started with a meetup for Boston-area people. It’s always a little strange to fly across the continent to meet with people from the same city, but it was really fun to meet people who I could concievably easily see again. In my past conferences, I haven’t really known anybody and would often wander around awkwardly at mealtimes, so I’ve gone a little bit overboard this time with setting up meals with people beforehand. It also helps that people are starting to reach out to me asking to meet. End result is that I’ve gotten to meet a lot of interesting people the last couple days, including:
- Trenton Bricken
- Jonathan Niles-Weed
- Amy Lu
- Alex Lu
- Alan Moses
- Philip Paquette
- David Yang
- Sam Sinai
- Elīna Locāne
- Neil Thomas
- Roshan Rao
- Nicholas Bhattacharya
I also ran into Neil Lawrence in the elevator and Andreas Krause in front of a poster today. I recognized Neil’s voice from Talking Machines. I’ve worked with several people who had previously worked with Andreas Krause, and refer to a few of his papers frequently, so I was very excited to hear that he’d read one of my papers.
Some papers I think are interesting
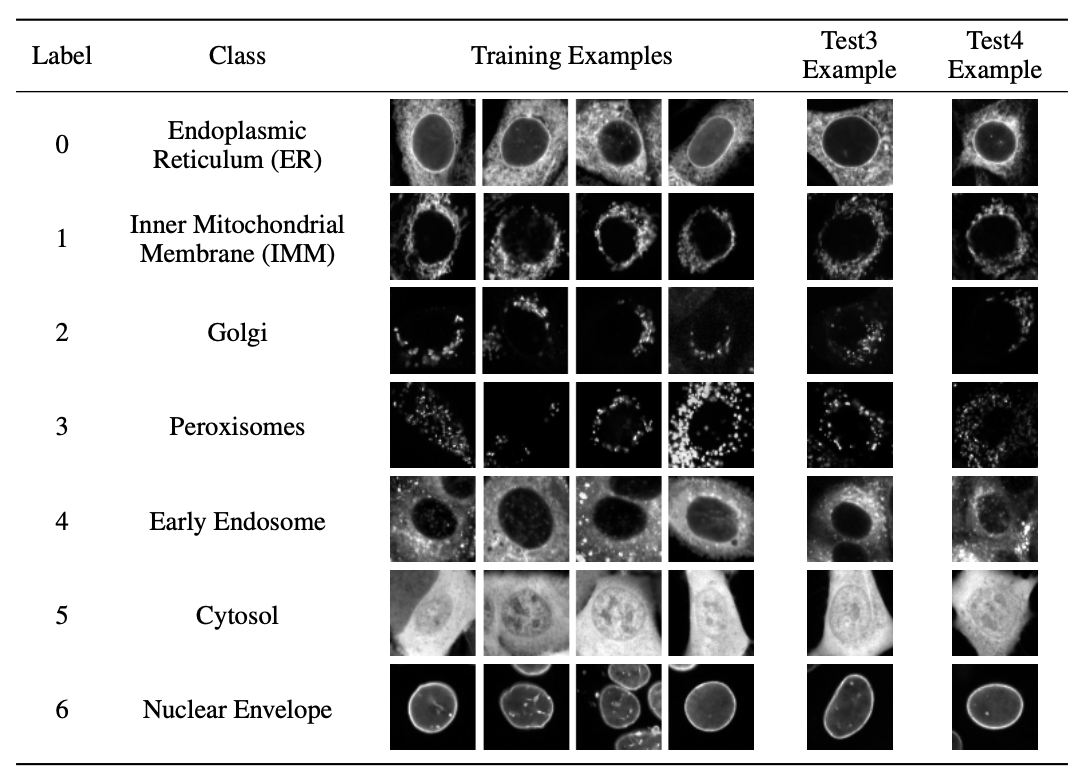
The Cells Out of Sample (COOS) dataset and benchmarks for measuring out-of-sample generalization of image classifiers
Alex X. Lu, Amy X. Lu, Wiebke Schormann, Marzyeh Ghassemi, David W. Andrews, Alan M. Moses.
Neural networks often learn confounders in biological data, such as the day of the experiment, the facility, or the position in a plate. The COOS dataset tests classifier performance when generalizing across these effects. Surprisingly, a vanilla supervised learner generalizes better than pre-trained models.
Single-Model Uncertainties for Deep Learning
Natasa Tagasovska, David Lopez-Paz.
Separately model aleatoric uncertainty using quantile regression and epistemic uncertainty by training a classifier to predict whether test examples are from the training distribution.
Image Synthesis with a Single (Robust) Classifier
Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Andrew Ilyas, Logan Engstrom, Aleksander Madry.
If you make your image classifier robust to adversarial examples, you can use it to generate realistic samples.
Adaptive Sequence Submodularity
Marko Mitrovic, Ehsan Kazemi, Moran Feldman, Andreas Krause, Amin Karbasi.
Problems that involve finding the optimal ordering of edges in a graph, such as choosing the order in which to recommend movies or video games, turn out to be submodular. Therefore, once the graph is computed, the order can be greedily optimized with strong optimality guarantees.
Computing Full Conformal Prediction Set with Approximate Homotopy
Eugene Ndiaye, Ichiro Takeuchi.
Transductive conformal regression traditionally involves calculating conformal scores for an intractible number of possible predictions. We can get around that by making some assumptions about the smoothness of the underlying predictive function. This results in slightly looser prediction intervals but maintains validity. Unlike inductive conformal regression methods, there’s no need to split the training data into a proper training set and a conformal scoring set.